Building a Scalable Data Analytics Pipeline
In today’s data-driven business landscape, processing and analyzing large volumes of data efficiently can determine an organization’s success. Building a scalable data analytics pipeline is critical for businesses seeking to gain a competitive edge. This guide explores how to construct such a pipeline using a combination of Talend, Fivetran, Snowflake, and dbt on Azure or AWS. With insights and best practices from experienced data engineers, you’ll learn how to build a robust pipeline that adapts to changing business needs. If you’re planning to scale your data infrastructure, it might be time to hire data engineers who specialize in modern tools like Talend, Fivetran, and Snowflake.

A Step-by-Step Guide to build a scalable Data Analytics Pipeline for Business Success
Introduction
The shift from traditional on-premises data storage to cloud-based data warehousing has revolutionized how businesses handle data. A scalable data analytics pipeline allows organizations to integrate, transform, and analyze data at scale, leading to improved decision-making and better business outcomes. This guide will help you create an efficient pipeline that can grow with your business.
Step-by-Step Guide
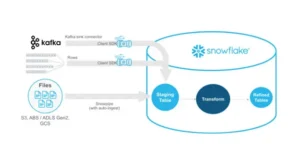
Step 1: Data Integration with Talend and/or Fivetran
Step 1: Data Integration with Talend and Fivetran
To build a scalable data analytics pipeline, the first step is data integration. Talend and Fivetran offer powerful tools for connecting disparate data sources and bringing them into a centralized location. Each has unique strengths that make them ideal for different use cases.
Talend: Talend’s drag-and-drop interface makes designing ETL (Extract, Transform, Load) processes easy. With its extensive library of connectors, you can integrate with various data sources, from databases and cloud storage to APIs and flat files. Talend’s flexibility is perfect for complex data workflows and custom transformations.
Fivetran: Fivetran is designed for simplicity and automation. It automatically syncs data from various sources to your chosen data warehouse, reducing the need for manual configuration. Its strength lies in its ability to maintain data consistency and adjust to schema changes without manual intervention.
Combining Talend’s customizability with Fivetran’s automation provides a reliable and flexible data integration layer. Depending on your needs, you can choose one or use both tools to meet your integration goals.


Step 2: Data Warehousing with Snowflake
Once the data is integrated, it needs to be stored in a scalable data warehouse. Snowflake, a cloud-based data warehousing platform, is an excellent choice. Its architecture separates storage and compute, allowing you to scale resources independently based on demand.
Snowflake’s Architecture: Snowflake’s multi-cluster architecture ensures high availability and lets you scale compute resources up or down depending on your workload. This flexibility is crucial for maintaining performance during peak usage and controlling costs during off-peak periods.
Security and Compliance: Snowflake provides robust security features, including encryption, role-based access control, and compliance with industry standards like GDPR and HIPAA. This makes it a secure choice for sensitive data.
Step 3: Data Transformation with dbt
Once the data is integrated, it needs to be stored in a scalable data warehouse. Snowflake, a cloud-based data warehousing platform, is an excellent choice. Its architecture separates storage and compute, allowing you to scale resources independently based on demand.
Snowflake’s Architecture: Snowflake’s multi-cluster architecture ensures high availability and lets you scale compute resources up or down depending on your workload. This flexibility is crucial for maintaining performance during peak usage and controlling costs during off-peak periods.
Security and Compliance: Snowflake provides robust security features, including encryption, role-based access control, and compliance with industry standards like GDPR and HIPAA. This makes it a secure choice for sensitive data.


Step 4: Monitoring and Optimization
A scalable data analytics pipeline requires continuous monitoring and optimization to ensure performance and reliability.
Monitoring with Talend and Snowflake: Talend offers monitoring tools to track ETL jobs, identify bottlenecks, and ensure data quality. Snowflake provides query profiling and resource usage insights to help optimize performance.
Optimization Best Practices: Implementing best practices like partitioning, clustering, and using the correct compute resources can significantly impact pipeline efficiency. Regularly reviewing and optimizing these aspects ensures your pipeline scales with your business needs.
Best Practices and Common Pitfalls
Here are some best practices to build a successful data analytics pipeline:
- Data Governance: Develop a well-defined data governance strategy. Ensure all ETL/ELT processes are properly documented, and perform regular data quality checks.
- Team Training: Invest in training your team to understand the pipeline’s architecture and purpose. This minimizes errors and ensures efficient operations.
Avoid common pitfalls, such as overcomplicating your pipeline design, which can lead to maintenance challenges. Also, don’t over-provision resources, as this can increase costs without adding value. Properly manage data security and compliance to avoid potential legal issues.
Building and managing a scalable data analytics pipeline requires the right talent. If you’re planning to implement or scale your setup, now might be the time to hire data engineers with expertise in Talend, Fivetran, Snowflake, and dbt.
Case Study: Transforming Data Analytics for a Giant Retailer
One of the largest national retailers, with hundreds of stores and a significant online presence, faced significant challenges due to scattered data from multiple sources—sales, customer feedback, inventory, and online interactions. This fragmentation made it hard for the retailer to understand their business needs and make informed decisions.

Work with Offsoar
If you’re ready to embark on this journey and need expert guidance, subscribe to our newsletter for more tips and insights, or contact us at Offsoar to learn how we can help you build a scalable data analytics pipeline that drives business success. Let’s work together to turn data into actionable insights and create a brighter future for your organization.


How LLMs Are Revolutionizing Text Mining and Data Extraction from Unstructured Data

How Businesses Use LLMs for Competitive Intelligence to Stay Ahead of the Curve

Maximizing Cost-Efficient Performance: Best Practices for Scaling Data Warehouses in Snowflake

Implementing Snowflake Data Governance for Scalable Data Security