Streamlining Data Transformation with DBT: An In-Depth Exploration
The significance of data in decision-making across businesses has grown, requiring the adoption of efficient data transformation practices.
Tools that simplify and manage data transformation modeling and orchestration are essential for modern data pipelines.
Building dependable, scalable, and maintainable data transformation workflows is now possible for organizations thanks to the development of dbt (Data Build Tool), an effective solution for these requirements.
In addition to highlighting dbt’s primary features for modeling, orchestrating, and documenting data pipelines, this article explores how dbt may help streamline data transformation processes
Introduction to DBT
dbt is an open-source command-line tool that helps data analysts and engineers transform the raw data in their data warehouses into valuable insights.
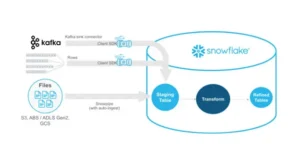
Unlike standard ETL (Extract, Transform, Load) solutions, dbt focuses primarily on the “Transform” part, assuming that data has already been loaded into a data warehouse like Snowflake, BigQuery, Redshift, or Databricks.
Users may create clean, analytics-ready datasets from raw data using dbt to compose modular SQL queries.
As part of a broader data transformation consulting service, dbt plays a critical role in helping organizations optimize their data workflows and maximize business insights. dbt manages model dependencies, automates transformation process execution, and generates documentation that offers insight into data pipelines.

Data Modelling with DBT
Dbt’s primary role is in its capacity to make data modeling efficient.
SQL files, or data models in dbt files, specify how unstructured data should be transformed into a more structured format.
Usually, these models are arranged in three layers:
- Staging Models:
- All downstream transformations are built upon staging models. Typically, they are made out of raw, standardized data tables that have been cleansed.
- Staging models in dbt generally follow naming standards (such as the
stg_prefix) and are stored in distinct folders to maintain the distinction between raw and transformed data.
- Intermediate Models:
- Intermediate models build upon staging models by implementing increasingly intricate transformations, aggregations, and business logic. The foundation of the data pipeline is made up of these models, which transform raw data into meaningful analytics-ready formats.
- Calculations, joins, and other operations that get the data ready for usage in dashboards and reports can be included in these models.
- Final Models/Mart Models:
- The results of the transformation process are final models. They represent the fully transformed datasets prepared for reporting and analysis. These models flow straight into data marts or business intelligence (BI) systems.
- Data analysts and business users may query and analyze the data more easily since final models are made to be simple and user-friendly.

Orchestrating Data Pipelines
Managing dependencies effectively and orchestrating the order of actions is one of the primary challenges in data transformation.
This is where dbt shines because of its automated orchestration features.
- DAGs and Model Dependencies:
- A Directed Acyclic Graph (DAG) is automatically created by dbt based on the dependencies between models. This DAG ensures that upstream models are finished before downstream models start by visualizing the order in which models should be executed.
- In addition to visualizing the workflow, the DAG is helpful for speed optimization and troubleshooting. When a model fails, the DAG helps determine which downstream models are impacted and require rerunning after resolving the issue.
- Incremental Models:
- Instead of analyzing the complete dataset, incremental models in dbt enable users to update just the rows that have changed since the last run. Large datasets primarily benefit from this since complete refreshes would require a lot of time and resources.
- To expedite the transformation process and minimize the burden, dbt users establish the logic for recognizing new or changed records for implementing incremental models.
- Validation and Testing:
- With the help of dbt, testing is integrated into the transformation process, enabling users to develop tests that verify the accuracy and quality of the data. Referential integrity, unique constraints, and null value detection are a few examples of standard tests.
- Dbt ensures that data transformations produce reliable results by running tests as part of the pipeline and identifying errors early in the process. Maintaining data quality requires this testing approach, particularly in intricate pipelines with multiple transformations.
- Scheduling and Execution:
- Although dbt doesn’t have scheduling built in, it works well with orchestration tools like Prefect and Apache Airflow, as well as cloud-native services like Google Cloud Composer and AWS Step Functions. This lets users manage dependencies throughout the data ecosystem, schedule dbt runs, and monitor pipeline performance.
- As used in conjunction with these orchestration tools, dbt may be configured to run manually as necessary, at predetermined intervals, or in response to external events.
Documentation and Version Control
Robust version control and extensive documentation are necessary for efficient data pipelines. Both of these objectives are met by DBT’s built-in features, which promote collaboration and transparency.

- Automated Document Generation:
- For every model, dbt automatically creates documentation that includes details about the input sources, output structures, and data transformation logic. Because it is written in HTML and can be hosted as a static website, stakeholders may quickly access this material.
- By giving models, columns, and tests unique descriptions, tags, and metadata, users may improve this documentation. This granularity ensures that everyone in the organization understands the data transformation process and what the outputs imply at the end.
- Data Lineage:
- As a lineage graph that shows how data moves through the pipeline from raw inputs to final outputs, the DAG generated by dbt also meets this function. This lineage is essential for debugging issues as they occur and understanding the effects of alterations to the data pipeline.
- Data lineage gives analysts confidence in the integrity and accuracy of reports and dashboards by assisting them in tracing the source of specific data items.
- Version Control and Collaboration:
- Integrating with Git, dbt promotes version control and allows teams to collaborate in a controlled setting on data transformation code. Git enables users to review code, keep track of changes, and, if needed, revert to earlier iterations.
- The modular structure of dbt allows team members to work on distinct models or components without interfering with each other’s work, thereby enhancing collaboration and promoting parallel development and faster iteration cycles.
Conclusion
Data teams’ approach to data transformation has been entirely transformed by dbt, which offers a robust foundation for modeling, orchestrating, and documenting data pipelines.
Its automated orchestration, integrated documentation, and modular design simplify the transformation process, facilitating the generation of transparent, scalable, and maintainable data workflows.
Organizations looking for a complete data transformation consulting service can rely on dbt as a central component of modern analytics infrastructure, enabling scalable and efficient transformation.
By using dbt, organizations can ensure that their data pipelines are reliable, flexible, and efficient in response to changing business requirements.
dbt offers the tools and best practices required to convert raw data into valuable insight, regardless of the scale of the project—from managing intricate company data environments to dealing with small datasets.
With its robust community support and extensibility, dbt is constantly evolving, providing new features and improvements that enable data teams to accomplish their objectives more easily.


How LLMs Are Revolutionizing Text Mining and Data Extraction from Unstructured Data

How Businesses Use LLMs for Competitive Intelligence to Stay Ahead of the Curve

Maximizing Cost-Efficient Performance: Best Practices for Scaling Data Warehouses in Snowflake

Implementing Snowflake Data Governance for Scalable Data Security