Best Practices for Building Reliable Snowflake Data Pipelines: Ensure Consistency and Performance
Building Reliable Snowflake Data Pipelines: Best Practices for Consistency and Performance
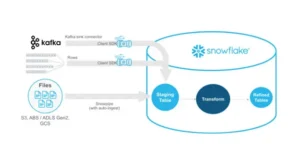
Data pipelines serve as the foundation of contemporary analytics, facilitating decision-making by converting raw data into actionable insights. Snowflake, with its powerful cloud-native data warehouse functionalities, is a favored option for enterprises pursuing scalability and dependability. To ensure proper implementation and ongoing optimization, many organizations choose to hire Snowflake experts who bring specialized knowledge of the platform.
This article will look at effective ways to enhance the reliability of Snowflake data pipelines. It offers practical guidance, accompanied by code examples, to assist in constructing robust pipelines, addressing task failures, and maintaining data consistency.
Common Challenges in Snowflake Data Pipelines
Key Components of AI-Driven Decision Intelligence
1. Disruption of Task Dependencies
When activities rely on upstream data, any delays or unavailability of that data might result in the failure of the entire pipeline. For example, if a data ingestion operation fails, subsequent transformation and loading processes may proceed with partial data.
2. Data Discrepancies Due to Interrupted Loads
Disruptions during data loading procedures, such as network complications or query timeouts, may result in tables being partly updated. This discrepancy may lead to erroneous reporting or ineffective analytics.
3. Partial Updates and Redundant data
Retries following failures may result in duplicate records if the pipeline is not engineered to accommodate idempotency. This poses significant challenges for real-time systems when precise, non-redundant data is essential.
Leveraging Snowflake Capabilities for Reliability
Snowflake provides several integrated functionalities to tackle these issues. Here is a method for their effective utilization:
1. Task Scheduling for Dependency Management
CREATE OR REPLACE TASK stage_data_task
WAREHOUSE = my_warehouse
SCHEDULE = 'USING CRON 0 * * * * UTC'
AS
INSERT INTO stage_table
SELECT * FROM raw_data;
CREATE OR REPLACE TASK transform_data_task
WAREHOUSE = my_warehouse
AFTER stage_data_task
AS
INSERT INTO transformed_table
SELECT * FROM stage_table;
2. Error Correction using TRY_CAST
SELECT TRY_CAST(column_name AS INTEGER) AS safe_column
FROM raw_data;
3. Atomic Transactions for Data Consistency
BEGIN;
INSERT INTO target_table (col1, col2)
SELECT col1, col2 FROM stage_table;
COMMIT;
Should a mistake arise during the INSERT process, the transaction will roll back, therefore preserving the target table unaltered.
Best Practices for Ensuring Data Consistency
1. Design Idempotent Loads
MERGE INTO target_table AS target
USING stage_table AS source
ON target.id = source.id
WHEN MATCHED THEN UPDATE SET target.value = source.value
WHEN NOT MATCHED THEN INSERT (id, value) VALUES (source.id, source.value);
2. Use CDC Snowflake Streams
CREATE STREAM shipment_updates ON TABLE shipments;
SELECT * FROM shipment_updates;
3. Use Retry Mechanisms and Robust Error Logging.
Illustrative Application: A Logistics Firm's Data Pipeline
Issue: An ETL process fails owing to erroneous data in a column. The pipeline ceases, rendering their dashboard obsolete.
Resolution:
- Error Management with TRY_CAST: The TRY_CAST function guarantees the secure omission of faulty data.
- Idempotent MERGE: The pipeline uses MERGE statements to update the shipment table while preventing data duplication.
- Task Scheduling: Dependencies are governed by Snowflake tasks to provide seamless pipeline execution.
Code Review:
-- Task 1: Load raw data into staging
CREATE OR REPLACE TASK load_raw_data
SCHEDULE = 'USING CRON 0 * * * * UTC'
AS
COPY INTO stage_table
FROM 's3://bucket/path';
-- Task 2: Transform data
CREATE OR REPLACE TASK transform_data
AFTER load_raw_data
AS
INSERT INTO transformed_table
SELECT TRY_CAST(column1 AS INTEGER) AS column1, column2
FROM stage_table;
-- Task 3: Update final table
CREATE OR REPLACE TASK update_final_table
AFTER transform_data
AS
MERGE INTO shipment_table AS target
USING transformed_table AS source
ON target.id = source.id
WHEN MATCHED THEN UPDATE SET target.status = source.status
WHEN NOT MATCHED THEN INSERT (id, status) VALUES (source.id, source.status);
Optimizing Pipeline Performance for Scalability
Ensuring reliability is only one aspect of the problem; your Snowflake data pipelines must also expand effectively as data volume increases. Optimize performance by utilizing Snowflake’s major features. – Optimize performance by utilizing Snowflake’s major features and, when needed, supplement your in-house teams with offshore data services to scale expertise cost-effectively.
- Clustering and Partitioning: Use clustering keys to enhance query speed on big tables by shortening scan times for frequently filtered columns.
- Automatic Scaling: Use Snowflake’s multi-cluster warehouses to dynamically scale computing resources according to workload demands, providing high availability during peak periods.
- Query Pruning: Query pruning designs pipelines with fewer, more focused queries rather than loading all data simultaneously. Use Snowflake’s metadata-driven trimming to handle just the necessary data.
Pro Tip: Use Snowflake’s resource monitoring tools to discover under- or over-provisioned resources, allowing you to fine-tune expenses while maintaining performance.
Monitoring and Alerting
Proactive monitoring is crucial for reliable pipelines. Snowflake has inherent tools, and other connectors can augment visibility:
1. Query History
2. Third-Party Monitoring Tools
Conclusion
Dedicate time to constructing robust pipelines; this investment yields precise insights and reliable operations.
To accelerate outcomes and maintain quality at scale, many enterprises hire Snowflake experts or partner with offshore data services that specialize in Snowflake optimization and data engineering.


How LLMs Are Revolutionizing Text Mining and Data Extraction from Unstructured Data

How Businesses Use LLMs for Competitive Intelligence to Stay Ahead of the Curve

Maximizing Cost-Efficient Performance: Best Practices for Scaling Data Warehouses in Snowflake

Implementing Snowflake Data Governance for Scalable Data Security