Snowflake Cloud Data Platform: Revolutionizing Data Warehousing in 2024
Snowflake: The Future of Cloud Data Warehousing for Scalable and Secure Data Management
With its unmatched scalability, flexibility, and user-friendliness, Snowflake has become a prominent solution in cloud-based data warehousing. Many businesses are also embracing offshore data warehousing models with Snowflake to reduce costs while ensuring global performance and compliance.
Although Snowflake’s design offers robust performance, organizations may further optimize speed and scalability by implementing several best practices and tactics. This article explores different strategies, emphasizing Snowflake’s salient characteristics and capabilities that enhance analytics performance.
1. Understanding the Architecture of Snowflake
It is crucial to comprehend the distinct architecture that Snowflake provides to optimize performance.
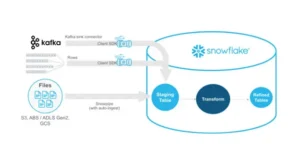
Snowflake has a shared-data, multi-cluster design that keeps computation and storage apart.
Because of this decoupling, both resources may scale independently, preventing storage constraints from impairing performance or vice versa.

- Storage Layer: Data is kept in a columnar, compressed format for effective storage and quick retrieval of huge datasets.
- Compute Layer: This is where virtual warehouse data processing occurs. Depending on workload demands, virtual warehouses may be scaled up (adding more compute resources) or scaled out (adding additional clusters).
- Cloud Services Layer: This layer regulates the entire functioning of the Snowflake environment by managing infrastructure, security, optimization, and metadata.
2. Optimising Query Efficiency

Query execution is one of the most essential areas for performance optimization. Many of Snowflake’s options can significantly improve query performance.
a) Keys for Clustering:
- Clustering keys are used to arrange the data within micro-partitions.
If you arrange the data according to certain columns, Snowflake will have to scan less data when your query executes.
This is especially helpful for large tables, where the volume of data scanned may affect query performance. - Determine which columns are often used in filters, joins, or aggregations to efficiently apply clustering keys. Monitor the performance of your queries and consider reclustering data as your dataset evolves.
b) Caching of Results:
- Snowflake caches query results for 24 hours.
Snowflake saves a lot of query time by returning the cached results if the same or a similar query is run within this time limit. - Ensure that dashboards or queries that run frequently take advantage of this functionality to get the most out of result caching. Refrain from making needless changes to queries that will hinder caching.
c) Query Pruning:
- Snowflake automatically prunes micro-partitions from a query that doesn’t belong there.
This procedure expedites query execution by reducing the amount of data scanned. - Although query pruning is primarily automated, this functionality may be more effective by creating tables with efficient clustering and reducing the number of broad-range queries used.
d) Materialized Views:
- Precomputed results of complex queries are stored in materialized views for quicker retrieval in later executions.
- Use materialized views for intricate joins, aggregations, or transformations that are frequently accessed. Remember that materialized views require refreshing, which might affect performance if incorrectly managed.
3. Effective Data Loading and Unloading

a) Bulk/Large scale loading:
- The COPY INTO command, designed for large-scale data intake, allows bulk loading with Snowflake. Instead of adding individual rows, this technique uses Snowflake’s parallel processing capabilities.
- Compress data before loading to reduce the quantity of data carried and stored. Upon loading, Snowflake automatically decompresses the data.
b) Data Staging:
- Before loading data into Snowflake from external sources, stage the data somewhere external (like Amazon S3). This approach speeds up data ingestion and simplifies data pipeline management.
- Use Snowpipe with Snowflake’s AUTO-INGEST function to continually load data from external stages as soon as it is available.
c) File sizes and partitions:
- Reduce file sizes to facilitate data loading. Snowflake suggests that for best loading performance, files be between 100 and 250 MB in size.
Larger files might cause slow performance because of the processing needed to break them into smaller micro-partitions, but smaller files could result in more overhead. - Partition your data according to dates or other logical standards to make loading and queries more effective.
4. Scaling Compute Resources

a) Automatic Scaling:
- For virtual warehouses, enable auto-scaling to add or remove clusters in response to query demand. This ensures that your system can function automatically while handling different workloads.
- While auto-scaling might help avoid bottlenecks during periods of high demand, the financial implications of scaling out, which requires additional computing resources, must be considered.
b) Size of Warehouse:
- Considering your business’s demands, select the right size for your virtual warehouses. Larger warehouses offer greater computational resources but at a higher expense.
- A bigger warehouse could be more effective for complicated workloads or lengthy queries, reducing query time overall. However, smaller warehouses are considered more cost-effective for simple queries or data-loading tasks.
c) Concurrency Scaling:
- Snowflake uses concurrent scaling to supply more computational resources when demand is high automatically. This functionality prevents resource contention from causing queries to lag.
- Customers with Enterprise Edition or above can use concurrency scaling credits for free, which makes it an essential tool for maintaining performance during peak periods.
5. Managing Data Archiving and Retention

a) Time Travel and Safety Measures:
- Using Snowflake’s Time Travel feature, you may query, clone, or restore data that has been changed or removed during a certain retention period. Long-term Time Travel activation, however, may affect performance and increase storage costs.
- Change the Time Travel settings by changing the retention duration according to your company’s requirements. For longer-term data recovery and retention, consider using Fail-Safe.
b) Data Archiving:
- One way to minimize the quantity of data that has to be scanned during queries is to archive outdated or seldom-used data. With Snowflake, you may store archived data that is readily available at a lower storage tier.
- Create effective data backup and archiving solutions using Snowflake’s Zero-Copy Cloning to save storage costs and optimize performance.
6. Monitoring and Optimisation

a) Query Profiling:
- Use Snowflake’s Query Profiler to analyze query performance, identify bottlenecks, and improve execution strategies. The profiler offers comprehensive insights into query execution, including the amount of data scanned, the duration of each step, and the resources utilized.
- Analyse query performance regularly and modify queries, database architecture, and resource allocation.
b) Resource Monitoring:
- Monitor virtual warehouses’ operations and modify their size, scaling strategy, and scheduling as needed to meet workload needs. Snowflake’s integrated monitoring tools offer real-time insights into resource use.
- Set up alerts for unusual increases in resource utilization or performance degradation to fix problems before they affect consumers.
Conclusion
To maximize performance and scalability in Snowflake, a mix of architectural understanding, efficient query design, effective data management, and proactive resource management is needed. By using Snowflake’s fundamental features, such as auto-scaling, query caching, and clustering keys, organizations can ensure the longevity of their data warehousing system, maintaining its affordability and adaptability while managing increasing workloads.
Whether you’re managing your infrastructure locally or through offshore data warehousing teams, getting the most out of Snowflake requires a commitment to frequent monitoring and optimization.


How LLMs Are Revolutionizing Text Mining and Data Extraction from Unstructured Data

How Businesses Use LLMs for Competitive Intelligence to Stay Ahead of the Curve

Maximizing Cost-Efficient Performance: Best Practices for Scaling Data Warehouses in Snowflake

Implementing Snowflake Data Governance for Scalable Data Security